
ガーディアンロボットプロジェクト
川西 康友
4. 多種のセンサを用いた環境認識技術
電力・計算性能の関係で,高度な環境認識処理をロボットに搭載したPCで処理することは難しい.そこで,ロボットに搭載したPCではデータの圧縮のみ行い,外部のサーバへとWi-Fi経由でデータを送信して処理するように実装した.図 4に示す認識機能により,何の物体がどこにあり,「誰がどこで何を話し,何をしているか」を3次元的に理解することができる.以下,詳細について述べる.
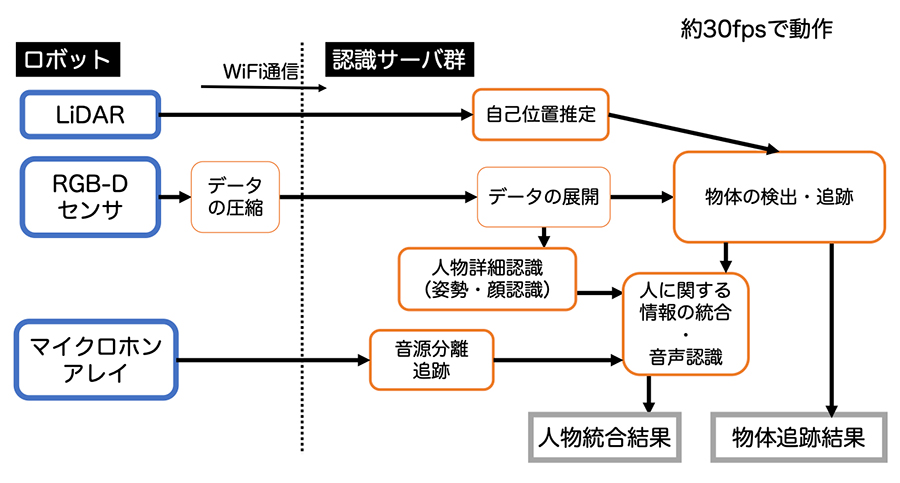
4.1 視覚センサによる周囲認識技術
視覚(RGB-D)センサからは2次元のカラー画像および深度画像が得られる.この情報をもとに,我々は,物体追跡,人物認識,人物姿勢推定,指差し対象推定,物体間の関係(シーングラフ)推定を統合した周囲環境認識システムを構築している.
物体認識はYOLOv8をベースとした物体検出器を用いて物体の名前と2次元画像中における領域を得て,各物体をBoT-SORT[4]により物体する.また,深度画像を参照してカメラから各物体までの距離を算出することにより,カメラ座標系での3次元位置を求める.そしてロボット(Keigan Ali)に搭載したLiDARによって算出された自己位置推定結果をもとに,世界座標系での物体位置を算出することで,「どこに何があるか」を3次元的に理解することができる.
近年の物体検出技術は,検出したい対象カテゴリの集合を定義し,それらを含むデータとアノテーションの組を大量に用意して学習することにより,精度良く実現できるようになってきた.しかし,実際に事前に用意できる物体カテゴリ(既知物体)は実世界に存在する物体カテゴリ数のうちのほんの一部であり,実世界には学習データに含まれない物体カテゴリ(未知物体)が多数存在する.通常,学習データに含まれない物体カテゴリに属する画像中の物体は無視されるか,学習データ中のどれかの物体カテゴリであると誤って検出されてしまう.我々は,そのような誤りを避けるため,学習データに含まれていない物体は未知であると出力する,Open-set認識技術を導入している.
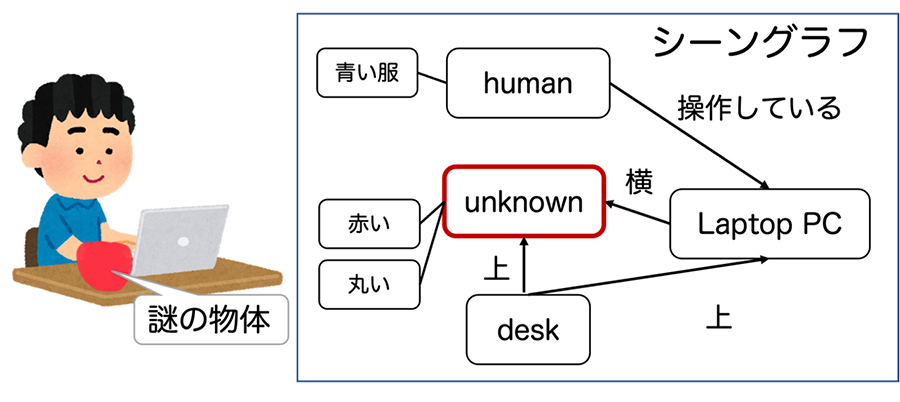
また,物体の名前と位置だけではなく,本システムでは「机の上にコップが乗っている」,「人がパソコンを持っている」など物体同士の関係も推定する.これら物体同士の関係は「主語・述語・目的語」の組で表現される一方,各物体を頂点,各関係を辺とみることによりグラフ構造で表現できることから,物体同士の関係を表したデータはシーングラフと呼ばれており,それを推定することはシーングラフ推定と呼ばれている.我々は,シーングラフ推定をOpen-set認識へと拡張した,Open-setシーングラフ推定技術[5]を提案しており,「机の上に何か知らないもの(unknown)が乗っている」といった出力を可能としている(図 5).
人の認識については,RGB-Dデータをもとに3次元姿勢推定することによって各人物の姿勢を推定し,頭部周辺から切り出した画像をもとに顔認識・顔向き認識をすることで,「誰が,どの様な姿勢で,どちらを向いているか」を認識する.また,人の意図を認識する一環として,人の指差し対象を推定する技術も実装している.指差し対象を推定するためには,人がどの方向を指さしているのか(指差し方向)の推定と,その先にある物体の特定が必要である.指差し方向の推定手法として,単一視点の映像から人の指差し方向を3次元ベクトルとして推定する手法[6]を提案している.それによって得られる3次元ベクトルと,人から各物体への3次元ベクトルとがなす角度をもとに,指差し対象を推定する手法を実装した.
4.2 聴覚センサによる音声認識技術
ロボットが人と対話するためには,周囲にいるどの人が何を話しているのかを理解する必要がある.そこで,16chマイクロホンアレイを用いて音源分離[7]を行い,人物追跡と音源分離結果を統合して,人物の方向と音源方向が一致した場合に,その人物が発話していると判断する.そして,その方向の音声強調をして他の音声を抑制したうえで,Whisper-large-v2[8]による音声認識を適用する.これにより,「どの人が何を話しているか」を認識できる.
認識結果の例
簡単ではあるが,図 6に,周囲環境結果の例を載せる.左上はシーングラフ推定結果の例であり,図中にクラス名は書かれていないが,関係を表す主語・述語・目的語がそれぞれ青枠,緑矢印,赤枠で表現されている.例えば,「人がシャツを着ている」などが表現されている.
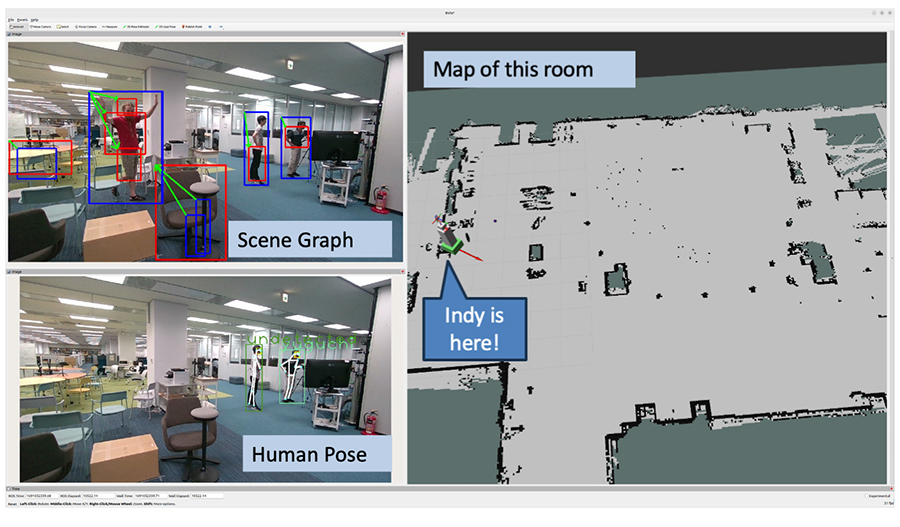
左下は人物認識結果であり,検出した人物の姿勢と,認識した人物の名前が表示されている.ここで,既知のどの人物にもマッチしなかった人物はunknownとして表示されている.右側は,自己位置推定結果であり,ロボットの位置が,正しく環境地図内で推定できている.
5. おわりに
理化学研究所ガーディアンロボットプロジェクトにおいて開発したロボットのひとつである,自律移動型対話ロボットIndyについて紹介した.Indyは,人に寄り添い,さりげなく支援することを目指したロボットである.本記事では,特に,主体的に行動を決定して動作するシステム及び,周囲環境認識に関して解説をした.
現状のロボットは,まだ限定的なシナリオを選択しながら動作することしか出来ない.将来的には,人と同じレベルで周囲の環境や状況を理解し,素晴らしい気遣いで人の生活がスムーズになるよう支援してくれるようなロボットが一般家庭に普及し,我々の生活に寄り添って生活を豊かにしてくれることを期待する.
参考文献
- N. Aharon, R. Orfaig, B.-Z. Bobrovsky
BoT-SORT: Robust Associations Multi-Pedestrian Tracking
arXiv preprint arXiv:2206.14651, 2022. - M. Sonogashira, M. Iiyama, Y. Kawanishi
Towards Open-Set Scene Graph Generation with Unknown Objects
IEEE Access, vol.10, pp.11574-11583, 2022. - S. Nakamura, Y. Kawanishi, S. Nobuhara, K. Nishino
DeePoint: Visual Pointing Recognition and Direction Estimation
The 19th International Conference on Computer Vision, pp. 20577-20587, 2023. - C.T. Ishi, C. Liu, J. Even, N. Hagita. (2016). “Hear- ing support system using environment sensor net- work,” IEEE/RSJ International Conference on Intel- ligent Robots and Systems, pp. 1275-1280, Oct., 2016.
- A. Radford, J. W. Kim, T. Xu, G. Brockman, C. McLeavey, I. Sutskever, “Robust Speech Recognition via Large-scale Weak Supervision.” International Con- ference on Machine Learning. PMLR, 2023.
【著者紹介】
川西 康友(かわにし やすとも)
国立研究開発法人理化学研究所
情報統合本部 ガーディアンロボットプロジェクト
感覚データ認識研究チーム チームリーダー
■著者略歴
- 2006年京都大学工学部情報学科 卒業
- 2008年京都大学大学院情報学研究科 修士課程修了
- 2012年京都大学大学院情報学研究科 博士課程修了(京都大学博士(情報学))
- 2012年京都大学学術情報メディアセンター 特定研究員
- 2014年名古屋大学未来社会創造機構特任 助教
- 2015年名古屋大学大学院情報科学研究科 助教
- 2017年名古屋大学大学院情報学研究科 助教
- 2020年名古屋大学大学院情報学研究科 講師
- 2021年国立研究開発法人理化学研究所 チームリーダー
- 2021年名古屋大学 客員准教授
- 2022年奈良先端科学技術大学院大学 客員教授
現在に至る.
ロボットによる周囲環境認識及び,人物追跡・属性認識・行動認識などの人物画像処理に関する研究に従事.特に,認識器の学習データに含まれていない,認識器にとっての未知物体の認識に関する研究に注力している.