
草薙 和也
3.4. 実施内容(結果と考察)
機械学習には多種多様な手法が提案されており、我々も有望と期待される複数の手法を試しているところである。ここでは近年のAIブームの火付け役となったニューラルネットワークに着目し、ニューラルネットワークをベースとした各手法とその結果を略述する。
① 1D-CNN
畳み込みニューラルネットワーク(CNN)は画像認識の分野でよく使われる教師あり学習の手法で、入力データに対してカーネルと呼ばれる行列を用いた畳み込みの計算を行うことによって特徴量を圧縮することができる。マッドロギングデータのような時系列データに対して時系列方向にカーネルを当てはめることで、時系列方向にデータを圧縮することができる。圧縮したデータを入力層、ラベルを出力層として学習を行い、生成された学習済みモデルにラベルを隠した未知のデータセットを入力して出力されるラベルの精度を評価する。
スタディでは現在のデータに基づいて将来の状態を分類する「予兆検知」ではなく、現在のデータに基づいて現在の状態を分類する「現象識別」から始めた。現在からΔt後に発生するイベントの予兆を検知するためにはt=Tのデータに対してt=T+Δtのラベルを対応させて学習・判断させるが、現象の識別はt=Tのデータに対してt=Tのラベルを対応させて学習・判断させる。理論的には予兆検知よりも現象識別のほうが難易度は低いと考えられ、1D-CNNの適用可能性評価のために現象識別を実施した。
計算実行の結果、学習段階において損失関数の減少が確認され、掘削データから抑留状態を表すパターンを学習していることが確認された。しかし未知のデータに対しての識別精度は表2の通りであり、ランダムにラベルを判断したケースと比較しても有意な識別精度の向上は見られなかった。これは使用したデータのうち離脱作業を含むデータ数が十分でないことが原因であると考えられる。そこで離脱作業を行っている区間のデータに対してData Augmentation(データ拡張)手法の一つであるOversamplingを適用することにより、学習データにおけるラベル1のデータ数を増やして計算を実行したところ、識別精度の向上が確認された。
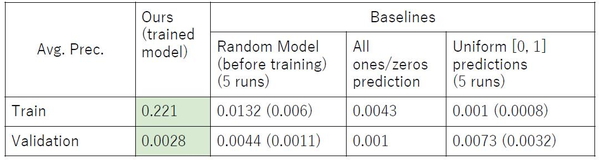
② Auto Encoder
教師なし学習の例として、Auto-Encoderを用いた。Auto Encoderは中間層の次元を入出力層の次元より小さく設定し、入力と出力を同じデータにすることで、入力データから出力データをより少ない情報量で再現するモデルを生み出す手法である。今回のケースでは入力層と出力層を正常掘削区間のデータとして学習させ、評価では未知データに対する学習済みモデルからの出力値と実測値の差から復元誤差を算出した。この手法では、学習済みモデルに抑留状態区間のデータを入力すると、復元誤差が大きくなることが期待される。
計算実行の結果、ラベル0のデータと比較してラベル1のデータに対する復元誤差(平均値)が約3倍大きくなる結果が得られた。これはそれぞれのラベルが付されたデータにおいて異なるパターンが表れていることを示しており、実際にラベルが0から1に変化する直前に復元誤差が立ち上がり、ラベルが変化した後では復元誤差が増加している様子が見て取れる。
③ ニューラルネットワーク
ニューラルネットワークは上で述べたCNNやAuto Encoderのベースとなる手法であり、ここでは①②と異なり時系列データを区間特徴量(周波数応答/統計量)に変換して入力データに用いた例を紹介する。掘削作業には鋼管の回転やポンプのストロークのように周期的な運動が含まれ、抑留の予兆は周波数領域にも現れることが予想される。また瞬間的なデータの変動を逐一追うのではなく、ある程度の時間幅の中での挙動に注目して分析するために平均や分散などの統計量を作成して入力データとした。本スタディでは中間層の数を1、2、3層と変化させて識別精度がどのように変化するかを評価した。
計算実行の結果を表3に示す。上から中間層が1層、2層、3層のケースとなっている。F1値*3での評価結果では層数に対して有意な差が認められないが、PrecisionやRecallにはある程度の差がみられた。本スタディでは識別するべきラベルが0か1の2通りしかないため、ニューラルネットワークの複雑さによって識別精度が大きく影響されなかったと考えられる。混合行列においてPrecisionやRecallに注目することは、実際の現場での運用を考えるうえで重要である。今回の例では、小さな抑留でも見逃すことなく検知するのか、それとも誤検知はできるだけ減らして重大な抑留のみ検知できれば良いとするのか、運用上での要求を考慮する必要がある。
*3混合行列を用いた予測結果の評価尺度の一つで、精度(Accuracy)と再現率(Recall)の調和平均で表される。
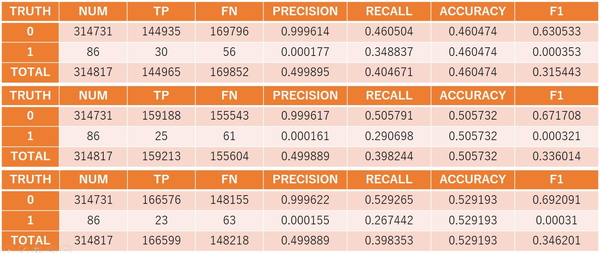
4. 終わりに
掘削データに機械学習を適用することによりトラブルの予兆検知を試みたが、現時点での成果は、すぐに現場への適用が検討される段階にはない。より良い学習済みモデルを作るために必要なのは、より多くの、より正確にラベル付けされたデータであることを再認識した。世界の石油開発業界では各社が保有する掘削データを共有しようとする動きもみられ、またリグの各所に追加のセンサーを設置してトラブルや機器の故障状態を分析する研究も多数報告されている。
掘削現場への適用を見据え、本研究の成果を実用化するにあたり、現場における運用方法に関する考察も必要である。デジタルトランスフォーメーションが叫ばれる中、石油開発に関してもまだまだデジタル技術適用による技術開発の余地があり、産業としての発展が期待される。
【著者略歴】
草薙 和也(くさなぎかずや)
独立行政法人 石油天然ガス・金属鉱物資源機構
デジタル推進グループ デジタル技術チーム
■略歴
1992年1月16日生
2016年3月 京都大学大学院 工学研究科 都市社会工学専攻 修士課程 修了
同年4月 独立行政法人石油天然ガス・金属鉱物資源機構 入構
■専門分野
Drilling Engineering(石油掘削)