
草薙 和也
3. 掘削データへのAI適用によるトラブル検知
掘削作業中のトラブルには掘削中の地層の地質性状を含め、その時々の様々な掘削条件が影響しているが、抑留についてはそのメカニズムが既に理解されているものがあり、発生前に何らかの予兆がマッドロギングデータに表れていると考えられるものが多い。鋼管の回転状況を反映するトルクを例にとると、坑壁が不安定で崩壊した際に坑内に落下する岩石との摩擦によりトルクの値は徐々に上昇し、最終的に回転が止まるといった過程が存在すると想定される。
これまで収集されてきたマッドロギングデータを詳細に解析することにより、データ内部に存在すると考えられる抑留の予兆を把握し、発生を事前に予測するモデルの作成を目的として、本研究では機械学習手法を用いた。本章では適用した機械学習の手法ごとに、手法と結果を概説する。
3.1. 実施体制
掘削の対象となる地下の特徴は不均質性が高く、フィールドごと、さらには坑井ごとに異なる。そうした条件のもと機械学習を用いて高い精度の解析を実現しようとすると、広範な操業環境を含むより大量のデータが必要となる。しかし石油開発においてはエネルギー市場への影響等から多くのデータが守秘情報とされ、自社が操業主体となっている案件のデータでなければ、その取り扱いに制約がかかることが多い。一方で各日本企業が操業主体として進めるプロジェクト数は限られるため、本件では、コンソーシアム形式として複数の参加企業からデータを提供していただいた。
JOGMECとJAMSTECの間で委託契約が締結されており、JAMSTECとの共同研究実施機関として東京大学、外注先として英国エジンバラ大学、協力機関として石油資源開発株式会社と国際石油開発帝石株式会社が参加している。
3.2. データ事前準備
参加企業からは合計で46坑井分のマッドロギングデータを収録した3810日分のcsvファイルが提供された(図3)。掘削データの事前準備において注意しなければならないのは、機械学習で重要な「高品質で大量の学習データ」という前提が成り立たないデータも多く含まれているということである。現場での作業は自然現象のみを理想的に反映しているわけではなく、その時々の現場状況等を勘案した人の判断が介入している。さらには、例えば逸泥トラブルであればどの程度までなら許容しながら掘削作業を進めるかというような、各社によって異なる”哲学”ともいうべきファクターも含まれている。また上述の通り、掘削作業が複雑な地下の地質を対象として行われており、その複雑な情報を反映するにはマッドロギングデータだけでは不十分なことも想定される。
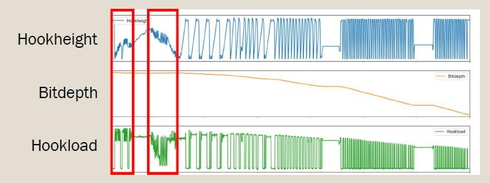
集められた掘削データが収録された当時はビッグデータの価値というのが現在ほど認識されておらず、機械学習の適用も想定されていなかったため、サンプリングレートや収録パラメータ、フォーマットといったデータ収録の標準も業界内において確立されていなかった。こうした理由から、まずは提供されたデータに対して事前準備として以下の整理を施した。
・共通して収録されているパラメータの抽出:合計で約20変数、うちどのパラメータの組み合わせを学習に用いるかはケースバイケース
・パラメータ名称および単位系の統一
・外れ値・欠損値が存在する測定区間の除去
3.3. ラベル付け
およそ全ての坑井掘削に際しては掘削日報が作成され、作業内容やトラブルに関する情報が記載されているので、それらを参照することでトラブルが生じている時間帯をおおよそ特定することが可能となる。しかし機械学習ではタイムステップ(今回では4秒周期)ごとにデータのラベルを付す必要があるので、最終的には時系列データを観察して以下のラベルを付した。
・0:正常掘進
・1:抑留状態(抑留からの離脱作業を含む)
次週に続く-
【著者略歴】
草薙 和也(くさなぎかずや)
独立行政法人 石油天然ガス・金属鉱物資源機構
デジタル推進グループ デジタル技術チーム
■略歴
1992年1月16日生
2016年3月 京都大学大学院 工学研究科 都市社会工学専攻 修士課程 修了
同年4月 独立行政法人石油天然ガス・金属鉱物資源機構 入構
■専門分野
Drilling Engineering(石油掘削)