
理事 技術委員
前田 賢一
1.はじめに
自動車の自動運転が話題に上る中、イメージセンサを利用した画像認識や画像計測が、そのための重要技術として注目されている。イメージセンサというと、CCDやCMOS、あるいはそれらを使ったカメラを思い浮かべるのが通常であるが、イメージセンサは外界の光情報(色・明るさ、など)を電気信号に変換する部分である。それは文字通り外界を「写す」機能を有する部分といえる。それだけでは、画像認識や画像計測を実現したことにはならない。人間はセンサとしての目の他に脳を持っており、これが外界の認識や理解に中心的な役割を果たしている [D.マッケイ,V.マッケイ編, 1993]。ここでは、その脳に相当する部分の実現方法のいくつかを紹介することにする。
2.自動車と画像センシング
自動運転をモチーフに自動車でのセンサ応用を問題にする際、画像が適しているかどうかを考えることは重要である。画像以外に、電波、超音波、レーザー、などのさまざまなセンサを利用することが可能である。距離の計測に目的を限定したとすると、それぞれのセンサで精度もコストも異なる。簡単な長所短所の比較を表1に示す。
| 画像 | 電波、レーザー、など | |
|---|---|---|
| 長所 | 人間が見ているものと同じ | 暗いところでも使える |
| 受動的センシング | (電波は霧の中でも使える) | |
| 短所 | 暗いところでは使えない | 人間とみているものが違う |
| (霧などの条件では使えない) | 光や電波を発する |
画像センシングはどこが良いのかを考えてみることにする。最大のメリットは、画像センシングで得られる情報が人間の得ている情報に近いという点である。人間はいわゆる五感をセンサとして持っているが、得られる情報の大半は視覚情報であると言われている。人間はそのように進化しており、また世界の人工物も人間に便利なように作られている。
実例として図1に示すような道路を想定してみる。前方に電柱やガードレールや車が見えるため、このまま直進するとどれかにぶつかる可能性がある状況である。仮にレーダーで障害物を検知したとすると、前方に電波を反射するものが検知されることだろう。そこで警告を出すかということが問題となる。画像であれば前方の車線がカーブしているので、道なりに進めば障害物は問題とならないことがわかる。これが画像センシングのメリットである。

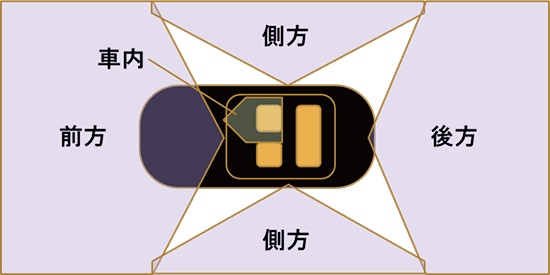
図2に監視領域を示す。それぞれの監視領域の目的は、概ね以下の通りである。
• 前方:障害物、飛び出し、などの検知
• 後方:バック時、車線変更時の障害物の検知
• 側方:車線変更時や狭い場所での障害物の検知
• 車内:運転手の状況の把握(今回は省略)
3.対象物の識別
対象物の識別は、画像センシングが最も得意とするところである。最近では深層学習(Deep Learning)と呼ばれる技術が主流となっている。ここでは深層学習の概略と応用の例を紹介する。
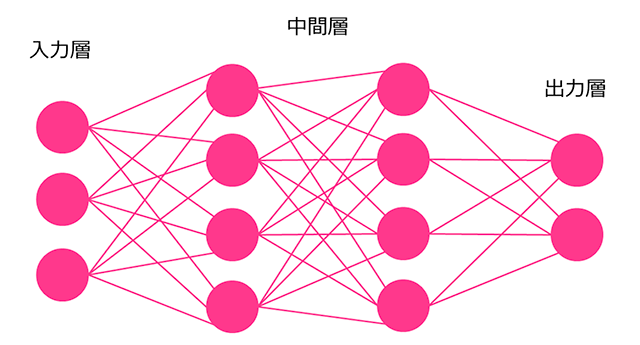
深層学習は、機械学習の一種で、その中でもニューラルネットワーク(Neural Network)というモデルを使うものである。さらに詳しく述べると、ニューラルネットワークの中でも階層型ニューラルネットワーク(図3参照)という構造に関するものである。
細かな部分を省略すると、深層学習は、大きく次の二つの要素からなる。
• 誤差逆伝播による学習
o 希望する出力が出るように結合の重みを調整
• 多層ネットワーク
o 最少4層以上で、多い場合は100層以上からなる「深い」ネットワーク
(1) 誤差逆伝播による学習
簡単化のため、3層のニューラルネットワークを考えることとする。また、出力も1個であるとする(図4参照)。
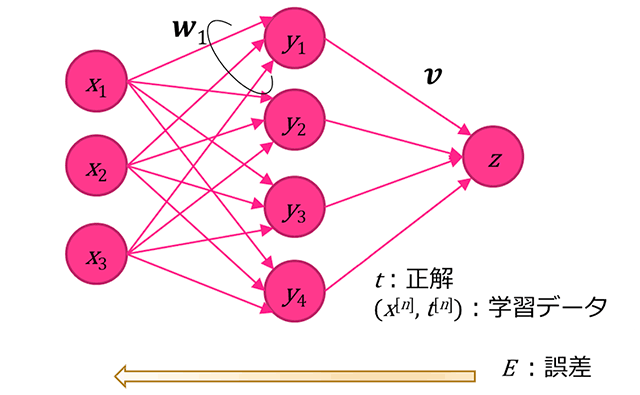
細かな計算は省略するが、学習は出力zと正解tとの誤差Eを少なくするように結合重みvとWとを順次修正する。この方法を最初に提案したのは甘利であり、確率的勾配降下法(Stochastic Gradient Descendent)と呼ばれていた [Amari, 1967]。
(2) 多層ネットワーク
ニューラルネットワークにはいろいろな構造が考えられているが、ここで使われているのは、信号が一方向に流れる階層型ニューラルネットワークである。流れる方向に沿ってニューロン素子が層状に並んでいるのが特徴である。この構造を最初に導入したのはRosenbrattであり、それを「単純」パーセプトロン(Perceptron)と呼んだ [Rosenbratt, 1958]。
深層学習で使われる階層は、最低でも4層である。よく使われるのは、たたみ込みニューラルネットワーク(Convolutional Neural Network: CNN)と呼ばれる構造で、図5に示すように、特徴抽出をするConvolution層(C層)とまとめるSubsampling層(S層あるいはPooling層)とが順に並ぶ構成になっている。
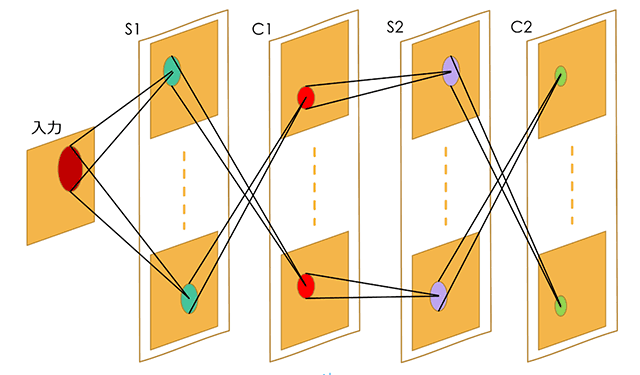
この構造は、福島によって提案されたものであり、ネオコグニトロン(Neocognitron)と名付けられた [Fukushima, 1980]
こういう仕組みを実際に利用した例を紹介する。以下はケンブリッジ大学で開発されたSegNetである [Badrinarayanan, etal, 2017]。深層学習と呼ぶのに相応しく、数多くの層が左右対称形に配置されている(図6参照)。左側がエンコーダで、Convolution、Batch Normalisation、ReLU、Poolingと多くの層が並んでいる。右側はデコーダで、検出された特徴をUpsamplingすることで元の画像の各点をラベル付けしている。この構造は、一般的にはU-Netと呼ばれる、セマンティックセグメンテーション(画像から同じ領域を切り出す仕組み)を実現するための方法である。
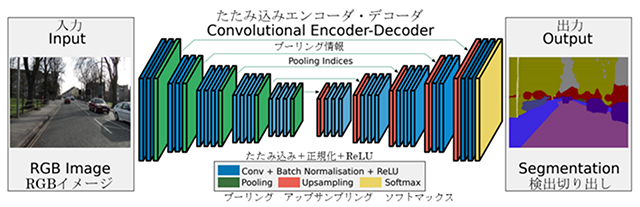
(R. Cipolla教授の許可を得てhttp://mi.eng.cam.ac.uk/projects/segnet/から修正)
図7に実際の入力画像と切り出された結果を示す。

(R. Cipolla教授の許可を得てhttp://mi.eng.cam.ac.uk/projects/segnet/から修正)
ここで紹介したのは一例にすぎないが、深層学習は一般的に物体認識で最も高い精度を達成している方式である。
4.動きの計測
自動車に必要な外界の情報として、対象物体の認識や切り出し以外に、外界物体の動きの情報がある。場合によっては対象物の認識以上に動きの情報は重要である。
自動車自身も動いており、外界にも動いているものがある。ここでの問題点は、自動車自身の動きによって止まっている外界の物体までもが動いて見えることにある。必要なことは、自動車自身の動きによって見かけ上動いて見えるものと、物体自体が動いているものとを区別するということである。
ここで使われる有力な方法として、オプティカルフロー(Optical Flow)がある [二宮芳樹,太田充彦, 1997]。オプティカルフローとは、画面の各点の動きベクトルである。簡単に言えば、画面の各点が比較的短い時間にどのように動くかという情報ということになる。計算方法は何通りかあり、ブロックマッチングによる追跡法、勾配法、Lucas-Kanade法、などが知られている [藤吉弘亘,他, 2013]
ここで車の前方をカメラで撮影しているシーンを想定してみる。そこに、右側から別の車が横切っているとする。その様子を模式的に図8に示す。
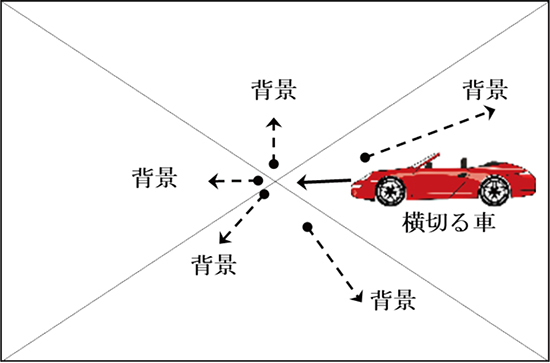
この場合、背景の動きベクトル(オプティカルフロー)は、画面の中心から湧き出してくる方向である(図中の破線で表示)。それに対して横切る車のオプティカルフローは、画面の右から左に向かう方向となる(図中の実線で表示)。
別の例として、高速道路を走行中に自車の広報をカメラで撮影しているシーンを想定してみる。複数車線あるので、追い越すことも追い越されることもある。隣の車線に追い越してくる車がいるとする。その様子を図9に模式的に描く。
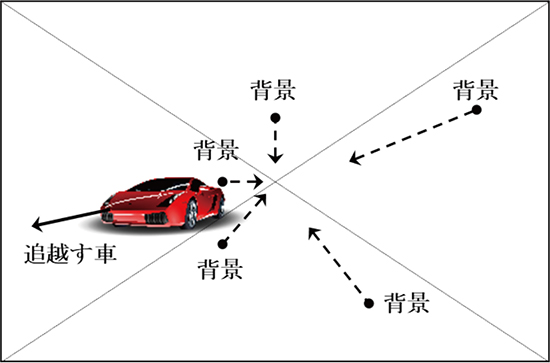
この場合、背景のオプティカルフローは、画面の中央に吸い込まれる方向である(図中の破線で表示)。それに対して、追い越してくる車のオプティカルフローは、逆に中央から湧き出す方向となる(図中の実線で表示)。
ここに示したように、オプティカルフローの状態によって、進行する際や車線変更する際に障害となり得る別の車を検出することが可能となる。ここで重要だったのは物体の種別ではなく、動きの情報であった。
次回に続く-
参考文献
Amari, S., 1967. Theory of adaptive pattern classifires. IEEE Transactions, Issue EC-16, pp. 299-307.
Badrinarayanan, V. etal, 2017. SegNet: A Deep Convolutional Encoder-Decoder Architecture for Scene Segmentation. IEEE Transactions on Pattern Analysis and Machine Intelligence, 39[12], pp. 2481-2495.
D.マッケイ,V.マッケイ編, 1993. ビハインド・アイ. 出版地不明:新曜社.
Fukushima, K., 1980. Noncognition: A Self-organizing Neural Network Model for a Mechanism of Pattern Recognition Unaffected by Shift in Position. Biological Cybernetics, Issue 36, pp. 193-202.
Onoguchi, K. etal, 1998. Planar projection stereopsis method for road extraction. IEICE TRANSACTIONS ON INFORMATION AND SYSTEMS, Issue E18D, pp. 1006-1018.
Rosenbratt, F., 1958. The Perceptron: A Probabilistic Model for Information Storage and Organization in the Brain. Psychological Review, 65[6], pp. 386-408.
Tomasi, C. Kanade, T., 1992. Shape and Motion from Image Streams under Orthography: a Factorization Method. International Journal of Computer Vision, 9[2], pp. 137-154.
実吉敬二, 2016. ステレオカメラによる自動運転車実現の可能性. エレクトロニクス実装学会誌, 19[6], pp. 398-402.
藤吉弘亘,他, 2013. 電子情報通信学会知識ベース「知識の森」2群-2編-4章 動画解析. [オンライン]
Available at: http://www.ieice-hbkb.org/portal/doc_590.html
[アクセス日: 10 4 2013].
二宮芳樹,太田充彦, 1997. オプティカルフローによる移動物体の検知. 出版地不明, 電子情報通信学会, pp. 25-31.
【著者紹介】
前田 賢一(まえだ けんいち)
一般社団法人 次世代センサ協議会 理事、技術委員
■略歴
1976年 東京工業大学大学院修士課程修了
1976年 東京芝浦電機株式会社(株式会社 東芝)入社
総合研究所(研究開発センター)所属
1989年~1991年 英国エジンバラ大学 客員研究員
1999年~2000年 東芝 関西研究センター長
2000年~2002年 電子情報通信学会 和文論文誌D 編集委員長
2002年~2004年 電子情報通信学会 情報・システムソサイエティ副会長(技術担当)
2004年~2011年 東芝 研究開発センター 技監
2004年~現在IEEE Senior Member
2005年~2008年 Treasurer, Japan Chapter of Computational Intelligence Society, IEEE
2007年 東京工業大学大学院博士課程修了(博士(工学))
2009年~現在 電子情報通信学会フェロー
2012年 Award Chair, ICPR 2012
2012年 Guest Editor, Special Issue, Pattern Recognition Letters
2016年 株式会社 東芝退職
フリーランスのコンサルタント(現職)
2017年~2020年 中央大学 客員研究員
2017年~現在一般社団法人 次世代センサ協議会 技術委員
2019年~現在一般社団法人 次世代センサ協議会 理事